Cfengine for Enterprise Configuration Management
April 1st, 2008 by Scott Lackey
Cfengine is known by many system administrators to be an excellent tool to automate manual tasks on UNIX and Linux-based machines. It also is the most comprehensive framework to execute administrative shell scripts across many servers running disparate operating systems. Although cfengine is certainly good for these purposes, it also is widely considered the best open-source tool available for configuration management. Using cfengine, sysadmins with a large installation of, say, 800 machines, can have information about their environment quickly that otherwise would take months to gather, as well as the ability to change the environment in an instant. For an initial example, if you have a set of Linux machines that need to have a different /etc/nsswitch.conf, and then have some processes restarted, there's no need to connect to each machine and perform these steps or even to write a script and run it on the machines once they are identified. You simply can tell cfengine that all the Linux machines running Fedora/Debian/CentOS with XGB of RAM or more need to use a particular /etc/nsswitch.conf until a newer one is designated. Cfengine can do all that in a one-line statement.
Cfengine's configuration management capabilities can work in several different ways. In this article, I focus on a make-it-so-and-keep-it-so approach. Let's consider a small hosting company configuration, with three administrators and two data centers (Figure 1).

Figure 1. How the Few Control the Many
Each administrator can use a Subversion/CVS sandbox to hold repositories for each data center. The cfengine client will run on each client machine, either through a cron job or a cfengine execution dæmon, and pull the cfengine configuration files appropriate for each machine from the server. If there is work to be done for that particular machine, it will be carried out and reported to the server. If there are configuration files to copy, the ones active on the client host will be replaced by the copies on the cfengine server. (Cfengine will not replace a file if the copy process is partial or incomplete.)
A cfengine implementation has three major components:
Version control: this usually consists of a versioning system, such as CVS or Subversion.
Cfengine internal components: cfservd, cfagent, cfexecd, cfenvd, cfagent.conf and update.conf.
Cfengine commands: processes, files, shellcommands, groups, editfiles, copy and so forth.
The cfservd is the master dæmon, configured with /etc/cfservd.conf, and it listens on port 5803 for connections to the cfengine server. This dæmon controls security and directory access for all client machines connecting to it. cfagent is the client program for running cfengine on hosts. It will run either from cron, manually or from the execution dæmon for cfengine, cfexecd. A common method for running the cfagent is to execute it from cron using the cfexecd in non-dæmon mode. The primary reason for using both is to engage cfengine's logging system. This is accomplished using the following:
*/10 * * * * /var/cfengine/sbin/cfexecd -F
as a cron entry on Linux (unless Solaris starts to understand */10). Note that this is fairly frequent and good only for a low number of servers. We don't want 800 servers updating within the same ten minutes.
The cfenvd is the “environment dæmon” that runs on the client side of the cfengine implementation. It gathers information about the host machine, such as hostname, OS and IP address. The cfenvd detects these factors about a host and uses them to determine to which groups the machine belongs. This, in effect, creates a profile for each machine that cfengine uses to determine what work to perform on each host.
The master configuration file for each host is cfagent.conf. This file can contain all the configuration information and cfengine code for the host, a subset of hosts or all hosts in the cfengine network. This file is often just a starting point where all configurations are stored in other files and “imported” into cfagent.conf, in a very similar fashion to Nagios configuration files. The update.conf file is the fundamental configuration file for the client. It primarily just identifies the cfengine server and gets a copy of the cfagent.conf.
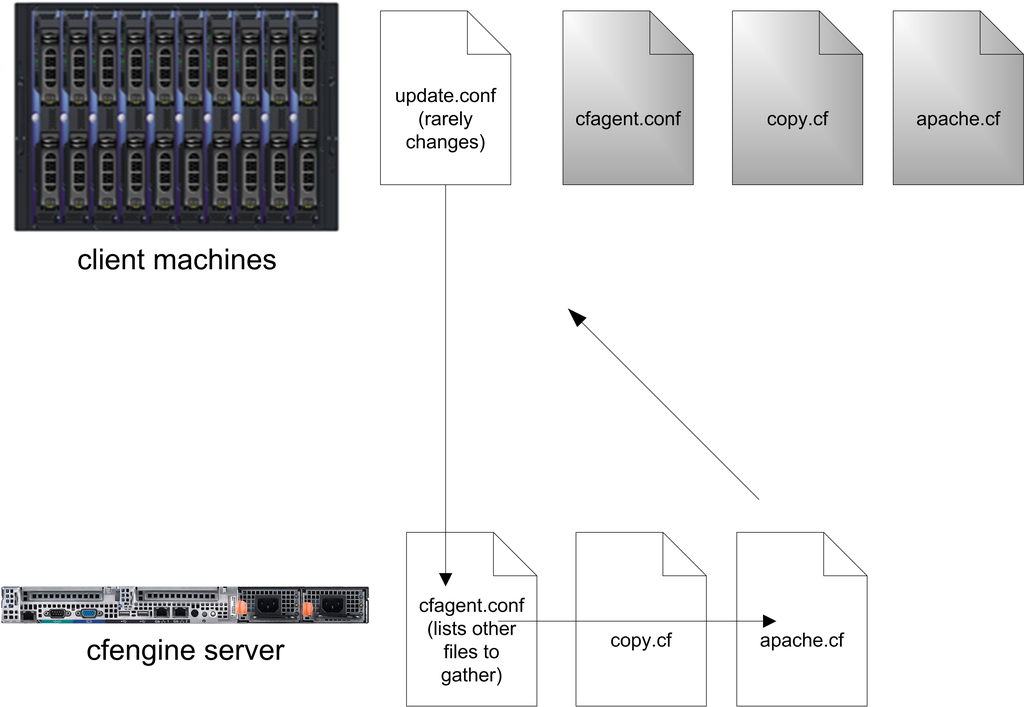
Figure 2. Automated Distribution of Cfengine Files
The update.conf file tells the cfengine server to deploy a new cfagent.conf file (and perhaps other files as well) if the current copy on the host machine is different. This adds some protection for a scenario where a corrupt cfagent.conf is sent out or in case there never was one. Although you could use cfengine to distribute update.conf, it should be copied manually to each host.
Cfengine “commands” are not entered on the command line. They make up the syntax of the cfengine configuration language. Because cfengine is a framework, the system administrator must write the necessary commands in cfengine configuration files in order to move and manipulate data. As an example, let's take a look at the files command as it would appear in the cfagent.conf file:
files:
/etc/passwd mode=644
owner=root action=fixall
/etc/shadow mode=600
owner=root action=fixall
This would set all machines' /etc/passwd and /etc/shadow files to the permissions listed in the file (644 and 600). It also would change the owner of the file to root and fix all of these settings if they are found to be different, each time cfengine runs. It's important to keep in mind that there are no group limitations to this particular files command. If cfengine does not have a group listed for the command, it assumes you mean any host. This also could be written as:
files:
any::
/etc/passwd mode=644
owner=root action=fixall
/etc/shadow mode=600
owner=root action=fixall
This brings us to an important topic in building a cfengine implementation: groups. There is a groups command that can be used to assign hosts to groups based on various criteria. Custom groups that are created in this way are called soft groups. The groups that are filled by the cfenvd dæmon automatically are referred to as hard groups. To use the groups feature of cfengine and assign some soft groups, simply create a groups.cf file, and tell the cfagent.conf to import it somewhere in the beginning of the file:
import:
any::
groups.cf
Cfengine will look in the default directory for the groups.cf file in /var/cfengine/inputs. Now you can create arbitrary groups based on any criteria. It is important to remember that the terms groups and classes are completely interchangeable in cfengine:
groups:
development = ( nfs01 nfs02 10.0.0.17 )
production = ( app01 app02 !development )
You also can combine hard groups that have been discovered by cfenvd with soft groups:
groups:
legacy = ( irix compiled_on_cygwin sco )
Let's get our testing setup in order. First, install cfengine on a server and a client or workstation. Cfengine has been compiled on almost everything, so there should be a package for your OS/distribution. Because the source is usually the latest version, and many versions are bug fixes, I recommend compiling it yourself. Installing cfengine gives you both the server and client binaries and utilities on every machine, so be careful not to run the server dæmon (cfservd) on a client machine unless you specifically intend to do that. After the install, you should have a /var/cfengine/ directory and the binaries mentioned previously.
Before any host can actually communicate with the cfengine server, keys must be exchanged between the two. Cfengine keys are similar to SSH keys, except they are one-way. That is to say, both the server and the client must have each other's public key in order to communicate. Years of sysadmin paranoia cause me to recommend manually copying all keys and trusting nothing. Copy /var/cfengine/ppkeys/localhost.pub from the server to all the clients and from the clients to the server in the same directory, renaming them /var/cfengine/ppkeys/root-10.11.0.1.pub, where the IP is 10.11.0.1.
On the server side, cfservd.conf must be configured to allow clients to access particular directories. To do this, create an AllowConnectionsFrom and an admit section:
#cfservd.conf
control:
AllowConnectionsFrom = ( 192.168.0.0/24 )
admit:
/configs/datacenter1 *.example1.com
/configs/datacenter2 *.example2.com
To test your example client to see whether it is connecting to the cfengine server, make sure port 5803 is clear between them, and run the server with:
cfservd -v -d2
And, on the client run:
cfagent -v --no-splay
This will give you a lot of debugging information on the server side to see what's working and what isn't.
Now, let's take a look at distributing a configuration file. Although cfengine has a full-featured file editor in the editfiles command, using this method for distributing configurations is not advised. The copy command will move a file from the server to the client machine with .cfnew appended to the filename. Then, once the file has been copied completely, it renames the file and saves the old copy as .cfsaved in the specified directory. Here's the copy command syntax:
copy:
class::
<>
dest=target-file
server=server
mode=mode
owner=owner
group=group
backup=true/false
repository=backup dir
recurse=number/inf/0
define=classlist
Only the dest= is required, along with the filename to save at the destination. These can be different. Here's another example:
copy:
linux::
${copydir}/linux/resolv.conf
dest=/etc/resolv.conf
server=cfengine.example1.com
mode=644
owner=root
group=root
backup=true
repository=/var/cfengine/cfbackup
recurse=0
define=copiedresolvdotconf
The last line in this copy statement assigns this host to a group called copiedresolvdotconf. Although we don't have to do anything after copying this particular file, we may want to do some action on all hosts that just had this file successfully sent to them, such as sending an e-mail or restarting a process. As another example, if you update a configuration file that is attached to a dæmon, you may want to send a SIGHUP to the process to cause it to reread the configuration file. This is common with Apache's httpd.conf or inetd.conf. If the copy is not successful, this server won't be added to the copiedresolvdotconf class. You can query all servers in the network to see whether they are members and, if not, find out what went wrong.
A great way to version control your config files is to use a cfengine variable for the filename being copied to control which version gets distributed. Such a line may look something like this:
copy:
linux::
${copydir}/linux/${resolv_conf}
Or, better yet, you can use cfengine's class-specific variables, whose scope is limited to the class with which they are associated. This makes copy statements much more elegant and can simplify changes as your cfengine files scale:
control:
# ${resolve_conf} value depends on context,
# is this a linux machine or hpux?
linux:: resolve_conf = ( "${copydir}"/linux/resolv.conf )
hpux:: resolve_conf = ( "${copydir}"/hpux/resolv.conf )
copy:
linux::
${resolve_conf}
Here is a full cfagent.conf file that makes use of everything I've covered thus far. It also adds some practical examples of how to do sysadmin work with cfengine:
# cfagent.conf
control:
actionsequence = ( files editfiles processes )
AddInstallable = ( cron_restart )
solaris:: crontab = ( /var/spool/cron/crontabs/root )
linux:: crontab = ( /var/spool/cron/root )
files:
solaris::
${crontab}
action=touch
linux::
${crontab}
action=touch
editfiles:
solaris::
{ ${crontab}
AppendIfNoSuchLine "0,10,20,30,40,50 * * * *
↪/var/cfengine/sbin/cfexecd -F"
DefineClasses "cron_restart"
}
linux::
{ ${crontab}
AppendIfNoSuchLine "0,10,20,30,40,50 * * * *
↪/var/cfengine/sbin/cfexecd -F"
#linux doesn't need a cron restart.
}
shellcommands:
solaris.cron_restart::
"/etc/init.d/cron stop"
"/etc/init.d/cron start"
import:
any::
groups.cf
copy.cf
The above is a full cfagent configuration that adds cfengine execution from cron to each client (if it's Linux or Solaris). So effectively, once you run cfengine manually for the first time with this cfagent.conf file, cfengine will continue to run every five minutes from that host, but you won't need to edit or restart cron. The control section of the cfagent.conf is where you can define some variables that will control how cfengine handles the configuration file. actionsequence tells cfengine what order to execute each command, and AddInstallable is a variable that holds soft groups that get defined later in the file in a “define” statement, such as after the editfiles command where the line is DefineClasses "cron_restart". The reason for using AddInstallable is sometimes cfengine skips over groups that are defined after command execution, and defining that group in the control section ensures that the command will be recognized throughout the configuration.
Being able to check configuration files out from a versioning system and distribute them to a set of servers is a powerful system administration tool. A number of independent tools will do a subset of cfengine's work (such as rsync, ssh and make), but nothing else allows a small group of system administrators to manage such a large group of servers. Centralizing configuration management has the dual benefit of information and control, and cfengine provides these benefits in a free, open-source tool for your infrastructure and application environments.