# In order to change your MAC address just type the following:
$ sudo ifconfig eth0 down hw ether 0A:0B:0C:0D:AA:BB
Note: "0A:0B:0C:0D:AA:BB" is just an example, you should put there the disired MAC address
Note: bringing down the interface (sudo ifconfig eth0 down) and them changing the mac address (sudo ifconfig eth0 hw ether 0A:0B:0C:0D:AA:BB) did not work, instead i did all in one line as shown above
# Now bring the interface back up, and you are ready to go.
$ sudo ifconfig eth0 up
Monday, October 27, 2008
Wednesday, October 15, 2008
Secured Remote Desktop/Application Sessions
Run graphical applications from afar, securely.
 Taken From: Linux Journal Contents #173, September 2008
Taken From: Linux Journal Contents #173, September 2008
There are many different ways to control a Linux system over a network, and many reasons you might want to do so. When covering remote control in past columns, I've tended to focus on server-oriented usage scenarios and tools, which is to say, on administering servers via text-based applications, such as OpenSSH. But, what about GUI-based applications and remote desktops?
Remote desktop sessions can be very useful for technical support, surveillance and remote control of desktop applications. But, it isn't always necessary to access an entire desktop; you may need to run only one or two specific graphical applications.
In this month's column, I describe how to use VNC (Virtual Network Computing) for remote desktop sessions and OpenSSH with X forwarding for remote access to specific applications. Our focus here, of course, is on using these tools securely, and I include a healthy dose of opinion as to the relative merits of each.
So, which approach should you use, remote desktops or remote applications? If you've come to Linux from the Microsoft world, you may be tempted to assume that because Terminal Services in Windows is so useful, you have to have some sort of remote desktop access in Linux too. But, that may not be the case.
Linux and most other UNIX-based operating systems use the X Window System as the basis for their various graphical environments. And, the X Window System was designed to be run over networks. In fact, it treats your local system as a self-contained network over which different parts of the X Window System communicate.
Accordingly, it's not only possible but easy to run individual X Window System applications over TCP/IP networks—that is, to display the output (window) of a remotely executed graphical application on your local system. Because the X Window System's use of networks isn't terribly secure (the X Window System has no native support whatsoever for any kind of encryption), nowadays we usually tunnel X Window System application windows over the Secure Shell (SSH), especially OpenSSH.
The advantage of tunneling individual application windows is that it's faster and generally more secure than running the entire desktop remotely. The disadvantages are that OpenSSH has a history of security vulnerabilities, and for many Linux newcomers, forwarding graphical applications via commands entered in a shell session is counterintuitive. And besides, as I mentioned earlier, remote desktop control (or even just viewing) can be very useful for technical support and for security surveillance.
Having said all that, tunneling X Window System applications over OpenSSH may be a lot easier than you imagine. All you need is a client system running an X server (for example, a Linux desktop system or a Windows system running the Cygwin X server) and a destination system running the OpenSSH dæmon (sshd).
Note that I didn't say “a destination system running sshd and an X server”. This is because X servers, oddly enough, don't actually run or control X Window System applications; they merely display their output. Therefore, if you're running an X Window System application on a remote system, you need to run an X server on your local system, not on the remote system. The application will execute on the remote system and send its output to your local X server's display.
Suppose you've got two systems, mylaptop and remotebox, and you want to monitor system resources on remotebox with the GNOME System Monitor. Suppose further you're running the X Window System on mylaptop and sshd on remotebox.
First, from a terminal window or xterm on mylaptop, you'd open an SSH session like this:
mick@mylaptop:~$ ssh -X admin-slave@remotebox
admin-slave@remotebox's password: **********
Last login: Wed Jun 11 21:50:19 2008 from dtcla00b674986d
admin-slave@remotebox:~$
Note the -X flag in my ssh command. This enables X Window System forwarding for the SSH session. In order for that to work, sshd on the remote system must be configured with X11Forwarding set to yes in its /etc/ssh/sshd.conf file. On many distributions, yes is the default setting, but check yours to be sure.
Next, to run the GNOME System Monitor on remotebox, such that its output (window) is displayed on mylaptop, simply execute it from within the same SSH session:
admin-slave@remotebox:~$ gnome-system-monitor &
The trailing ampersand (&) causes this command to run in the background, so you can initiate other commands from the same shell session. Without this, the cursor won't reappear in your shell window until you kill the command you just started.
At this point, the GNOME System Monitor window should appear on mylaptop's screen, displaying system performance information for remotebox. And, that really is all there is to it.
This technique works for practically any X Window System application installed on the remote system. The only catch is that you need to know the name of anything you want to run in this way—that is, the actual name of the executable file.
If you're accustomed to starting your X Window System applications from a menu on your desktop, you may not know the names of their corresponding executables. One quick way to find out is to open your desktop manager's menu editor, and then view the properties screen for the application in question.
For example, on a GNOME desktop, you would right-click on the Applications menu button, select Edit Menus, scroll down to System/Administration, right-click on System Monitor and select Properties. This pops up a window whose Command field shows the name gnome-system-monitor.
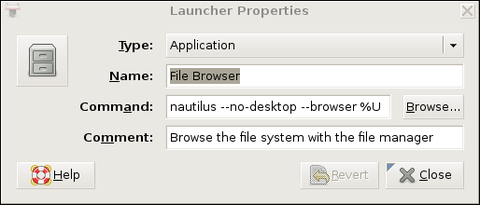
Figure 1 shows the Launcher Properties, not for the GNOME System Monitor, but instead for the GNOME File Browser, which is a better example, because its launcher entry includes some command-line options. Obviously, all such options also can be used when starting X applications over SSH.
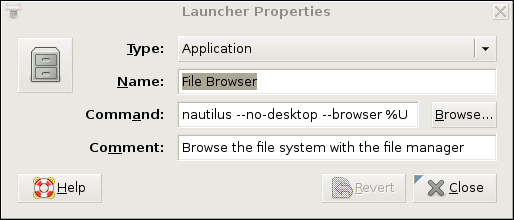
Figure 1. Launcher Properties for the GNOME File Browser (Nautilus)
If this sounds like too much trouble, or if you're worried about accidentally messing up your desktop menus, you simply can run the application in question, issue the command ps auxw in a terminal window, and find the entry that corresponds to your application. The last field in each row of the output from ps is the executable's name plus the command-line options with which it was invoked.
Once you've finished running your remote X Window System application, you can close it the usual way (selecting Exit from its File menu, clicking the x button in the upper right-hand corner of its window and so forth). Don't forget to close your SSH session too, by issuing the command exit in the terminal window where you're running SSH.
Now that I've shown you the preferred way to run remote X Window System applications, let's discuss how to control an entire remote desktop. In the Linux/UNIX world, the most popular tool for this is Virtual Network Computing, or VNC.
Originally a project of the Olivetti Research Laboratory (which was subsequently acquired by Oracle and then AT&T before being shut down), VNC uses a protocol called Remote Frame Buffer (RFB). The original creators of VNC now maintain the application suite RealVNC, which is available in free and commercial versions, but TightVNC, UltraVNC and GNOME's vino VNC server and vinagre VNC client also are popular.
VNC's strengths are its simplicity, ubiquity and portability—it runs on many different operating systems. Because it runs over a single TCP port (usually TCP 5900), it's also firewall-friendly and easy to tunnel.
Its security, however, is somewhat problematic. VNC authentication uses a DES-based transaction that, if eavesdropped-on, is vulnerable to optimized brute-force (password-guessing) attacks. This vulnerability is exacerbated by the fact that many versions of VNC support only eight-character passwords.
Furthermore, VNC session data usually is transmitted unencrypted. Only a couple flavors of VNC support TLS encryption of RFB streams, and it isn't clear how securely TLS has been implemented even in those. Thus, an attacker using a trivially hacked VNC client may be able to reconstruct and view eavesdropped VNC streams.
Luckily, as it operates over a single TCP port, VNC is easy to tunnel through SSH, through Virtual Private Network (VPN) sessions and through TLS/SSL wrappers, such as stunnel. Let's look at a simple VNC-over-SSH example.
To tunnel VNC over SSH, your remote system must be running an SSH dæmon (sshd) and a VNC server application. Your local system must have an SSH client (ssh) and a VNC client application.
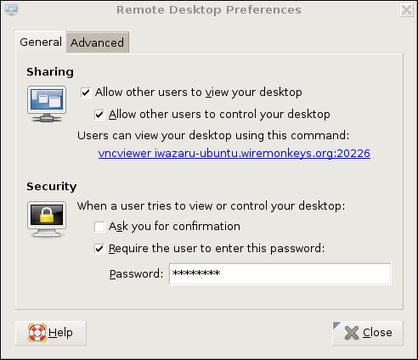
Our example remote system, remotebox, already is running sshd. Suppose it also has vino, which is also known as the GNOME Remote Desktop Preferences applet (on Ubuntu systems, it's located in the System menu's Preferences section). First, presumably from remotebox's local console, you need to open that applet and enable remote desktop sharing. Figure 2 shows vino's General settings.
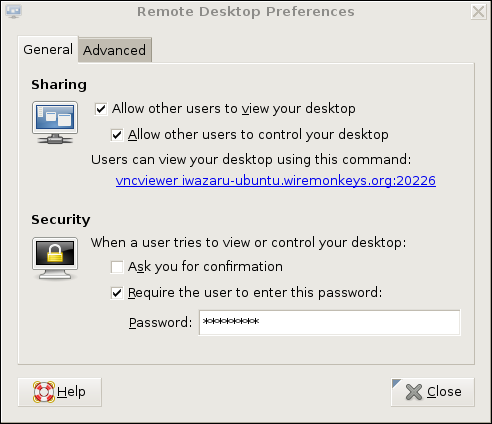
Figure 2. General Settings in GNOME Remote Desktop Preferences (vino)
If you want to view only this system's remote desktop without controlling it, uncheck Allow other users to control your desktop. If you don't want to have to confirm remote connections explicitly (for example, because you want to connect to this system when it's unattended), you can uncheck the Ask you for confirmation box. Any time you leave yourself logged in to an unattended system, be sure to use a password-protected screensaver!
vino is limited in this way. Because vino is loaded only after you log in, you can use it only to connect to a fully logged-in GNOME session in progress—not, for example, to a gdm (GNOME login) prompt. Unlike vino, other versions of VNC can be invoked as needed from xinetd or inetd. That technique is out of the scope of this article, but see Resources for a link to a how-to for doing so in Ubuntu, or simply Google the string “vnc xinetd”.
Continuing with our vino example, don't close that Remote Desktop Preferences applet yet. Be sure to check the Require the user to enter this password box and to select a difficult-to-guess password. Remember, vino runs in an already-logged-in desktop session, so unless you set a password here, you'll run the risk of allowing completely unauthenticated sessions (depending on whether a password-protected screensaver is running).
If your remote system will be run logged in but unattended, you probably will want to uncheck Ask you for confirmation. Again, don't forget that locked screensaver.
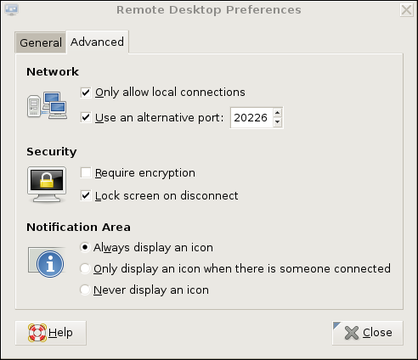
We're not done setting up vino on remotebox yet. Figure 3 shows the Advanced Settings tab.
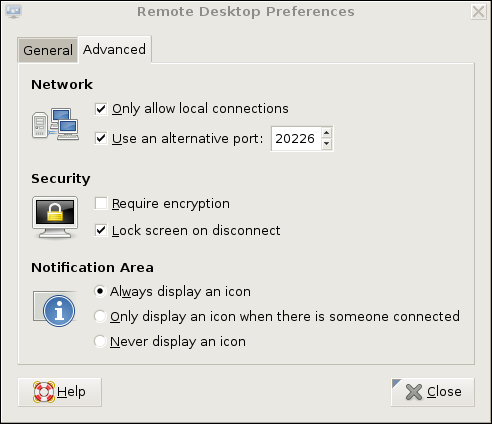
Figure 3. Advanced Settings in GNOME Remote Desktop Preferences (vino)
Several advanced settings are particularly noteworthy. First, you should check Only allow local connections, after which remote connections still will be possible, but only via a port-forwarder like SSH or stunnel. Second, you may want to set a custom TCP port for vino to listen on via the Use an alternative port option. In this example, I've chosen 20226. This is an instance of useful security-through-obscurity; if our other (more meaningful) security controls fail, at least we won't be running VNC on the obvious default port.
Also, you should check the box next to Lock screen on disconnect, but you probably should not check Require encryption, as SSH will provide our session encryption, and adding redundant (and not-necessarily-known-good) encryption will only increase vino's already-significant latency. If you think there's only a moderate level of risk of eavesdropping in the environment in which you want to use vino—for example, on a small, private, local-area network inaccessible from the Internet—vino's TLS implementation may be good enough for you. In that case, you may opt to check the Require encryption box and skip the SSH tunneling.
(If any of you know more about TLS in vino than I was able to divine from the Internet, please write in. During my research for this article, I found no documentation or on-line discussions of vino's TLS design details whatsoever—beyond people commenting that the soundness of TLS in vino is unknown.)
This month, I seem to be offering you more “opt-out” opportunities in my examples than usual. Perhaps I'm becoming less dogmatic with age. Regardless, let's assume you've followed my advice to forego vino's encryption in favor of SSH.
At this point, you're done with the server-side settings. You won't have to change those again. If you restart your GNOME session on remotebox, vino will restart as well, with the options you just set. The following steps, however, are necessary each time you want to initiate a VNC/SSH session.
On mylaptop (the system from which you want to connect to remotebox), open a terminal window, and type this command:
mick@mylaptop:~$ ssh -L 20226:remotebox:20226 admin-slave@remotebox
OpenSSH's -L option sets up a local port-forwarder. In this example, connections to mylaptop's TCP port 20226 will be forwarded to the same port on remotebox. The syntax for this option is “-L [localport]:[remote IP or hostname]:[remoteport]”. You can use any available local TCP port you like (higher than 1024, unless you're running SSH as root), but the remote port must correspond to the alternative port you set vino to listen on (20226 in our example), or if you didn't set an alternative port, it should be VNC's default of 5900.
That's it for the SSH session. You'll be prompted for a password and then given a bash prompt on remotebox. But, you won't need it except to enter exit when your VNC session is finished. It's time to fire up your VNC client.
vino's companion client, vinagre (also known as the GNOME Remote Desktop Viewer) is good enough for our purposes here. On Ubuntu systems, it's located in the Applications menu in the Internet section. In Figure 4, I've opened the Remote Desktop Viewer and clicked the Connect button. As you can see, rather than remotebox, I've entered localhost as the hostname. I've also entered port number 20226.
Figure 4. Using vinagre to Connect to an SSH-Forwarded Local Port
When I click the Connect button, vinagre connects to mylaptop's local TCP port 20226, which actually is being listened on by my local SSH process. SSH forwards this connection attempt through its encrypted connection to TCP 20226 on remotebox, which is being listened on by remotebox's vino process.
At this point, I'm prompted for remotebox's vino password (shown in Figure 2). On successful authentication, I'll have full access to my active desktop session on remotebox.
To end the session, I close the Remote Desktop Viewer's session, and then enter exit in my SSH session to remotebox—that's all there is to it.
This technique is easy to adapt to other versions of VNC servers and clients, and probably also to other versions of SSH—there are commercial alternatives to OpenSSH, including Windows versions. I mentioned that VNC client applications are available for a wide variety of platforms; on any such platform, you can use this technique, so long as you also have an SSH client that supports port forwarding.
Thus ends my crash course on how to control graphical applications over networks. I hope my examples of both techniques, SSH with X forwarding and VNC over SSH, help you get started with whatever particular distribution and software packages you prefer. Be safe!
Friday, October 10, 2008
Adding a User to a Group - Linux
Q. How can I add a user to a group under Linux operating system?
A. You can use useradd or usermod commands to add a user to a group. useradd command creates a new user or update default new user information. usermod command modifies a user account i.e. it is useful to add user to existing group. There are two types of group. First is primary user group and other is secondary group. All user account related information is stored in /etc/passwd, /etc/shadow and /etc/group files to store user information.
useradd example - Add a new user to secondary group
Use useradd command to add new users to existing group (or create a new group and then add user). If group does not exist, create it. Syntax:useradd -G {group-name} username
Create a new user called vivek and add it to group called developers. First login as a root user (make sure group developers exists), enter:# grep developers /etc/group
Output:
developers:x:1124:
If you do not see any output then you need to add group developers using groupadd command:# groupadd developers
Next, add a user called vivek to group developers:# useradd -G developers vivek
Setup password for user vivek:# passwd vivek
Ensure that user added properly to group developers:# id vivekOutput:
uid=1122(vivek) gid=1125(vivek) groups=1125(vivek),1124(developers)
Please note that capital G (-G) option add user to a list of supplementary groups. Each group is separated from the next by a comma, with no intervening whitespace. For example, add user jerry to groups admins, ftp, www, and developers, enter:# useradd -G admins,ftp,www,developers jerry
useradd example - Add a new user to primary group
To add a user tony to group developers use following command:# useradd -g developers tony
# id tony
uid=1123(tony) gid=1124(developers) groups=1124(developers)
Please note that small -g option add user to initial login group (primary group). The group name must exist. A group number must refer to an already existing group.
usermod example - Add a existing user to existing group
Add existing user tony to ftp supplementary/secondary group with usermod command using -a option ~ i.e. add the user to the supplemental group(s). Use only with -G option :
# usermod -a -G ftp tonyChange existing user tony primary group to www:# usermod -g www tony
Taken From: http://www.cyberciti.biz/faq/howto-linux-add-user-to-group/
Wednesday, October 1, 2008
Storing Object Oriented Data on a Database
Relational databases are really great for storing and retrieving data, but sometimes, they aren't quite up to the task. Joe Celko, whose SQL for Smarties books are among my favorites, dedicated an entire volume to the issue of trees and hierarchies. These data structures might be common and useful in most programming languages, but they can be difficult to model as tables, particularly if you care about efficient use of the database. Things become even trickier if you're dealing with a number of related, but distinct, types of entities, such as different types of employees or different types of vehicles.
One way to solve this problem is not to use relational databases. Objects can be quite good at handling trees and arrays, as well as inheritance hierarchies. Furthermore, object databases do exist, and the Python-based Zope application framework has demonstrated that it's even possible to have object databases in production. Gemstone's demonstration of Ruby running on top of its Smalltalk VM, with its accompanying object database, means that Ruby programmers soon might have access to similar technology.
But, object databases still are far from the mainstream. Most Web developers have access to a relational database, and not much else. Is there anything that we can do for these people?
This month, we take a look at two different ways we can handle data that doesn't quite fit into a relational database. These techniques are quite different from one another, and they don't even come close to the full range of possibilities you can get with a relational database. But, they both work and are used in production environments—and if your data doesn't seem to fit into standard database paradigms, you might want to consider one of them.
PostgreSQL's Table Inheritance
Some data-modeling issues are typically even harder to deal with. For example, a classic introduction to the world of object-oriented programming describes a human resources department. The HR department tracks employees, all of whom have some common characteristics. But, some employees are programmers, some are secretaries, and some are managers—and each of the employee types has specific data that needs to be associated with them.
In an object-oriented world, it's easy to model this. You create an employee class, and then create multiple subclasses of programmer, secretary and manager. Subclassing creates an “is-a” relationship, such that a programmer is an employee. This means that programmers have all the attributes of an employee, but also have some additional characteristics that distinguish them from an ordinary employee. With these subclasses in place, we then can create an array (or any other data structure) of people in our company, knowing that although some are programmers and others are secretaries, they're all employees and can be treated as such.
Translating this idea to the world of relational databases can be a bit tricky. One solution is to use inheritance in your database tables. PostgreSQL has done this for years; thus, it's called an object-relational database by many users. You can do the following in PostgreSQL, for example:
CREATE TABLE Employees (
id SERIAL,
first_name TEXT NOT NULL,
last_name TEXT NOT NULL,
email_address TEXT NOT NULL,
PRIMARY KEY(id),
UNIQUE(email_address)
);
CREATE TABLE Programmers (
main_language TEXT NOT NULL
) INHERITS(Employees);
CREATE TABLE Secretaries (
words_per_minute INTEGER NOT NULL
) INHERITS(Employees);
INSERT INTO Employees (first_name, last_name, email_address)
VALUES ('George', 'Washington', 'georgie@whitehouse.gov');
INSERT INTO Programmers (first_name, last_name,
email_address, main_language)
VALUES ('Linus', 'Torvalds', 'torvalds@osdl.org', 'C');
INSERT INTO Secretaries (first_name, last_name,
email_address, words_per_minute)
VALUES ('Condoleezza', 'Rice', 'rice@state.gov', 10);
If we ask for all employees in the system, we'll get all three of the people we have entered:
atf=# select * from employees;
id first_name last_name email_address
----+------------+------------+------------------------
1 George Washington georgie@whitehouse.gov
2 Linus Torvalds torvalds@osdl.org
3 Condoleezza Rice rice@state.gov
(3 rows)
Of course, this query shows only the columns of the Employees table, which are common to that table and to those that inherit from it. If we want to find out how many words per minute someone types, we must address that query specifically to the Secretaries table:
atf=# select * from secretaries;
id first_name last_name email_address words_per_minute
----+------------+-----------+----------------+------------------
3 Condoleezza Rice rice@state.gov 10
(1 row)
Notice that the id column for all three tables, which was defined as SERIAL (that is, a nonrepeating incrementing integer), is unique across all three tables.
Polymorphic Associations
The way that PostgreSQL has integrated this type of object hierarchy into its relational system is impressive, flexible and useful. And yet, because it is unique to PostgreSQL, it means that no higher-level, database-agnostic application framework can support it. This especially is true in Ruby on Rails, which tries to treat all databases as similar or identical, going so far as to encourage programmers to use a Ruby-based domain-specific language (migrations) to create and modify database definitions. Using PostgreSQL's inheritance features might work, but it will take a fair amount of twisting to make it compatible with Rails.
Besides, Rails already has a feature, known as polymorphic associations, that lets us work with distinct types of items as if they were part of a single class. This isn't the same as an object hierarchy—we can't say that secretaries and programmers are both types of employees. But, we can say that secretaries and programmers are both employable and treat them as similar via that description.
To begin, you might remember that Rails has something known as associations, which allow us to connect one model to another. For example, let's say that each company has one or more employees. Thus, we can create some simple models. We can generate migrations with:
./script/generate model company name:string
./script/generate model employee first_name:string
last_name:string email_address:string company_id:integer
Then, we can turn the automatically generated migration files into actual database tables with the following:
rake db:migrate
Now, we can indicate that each company can have one or more employees by modifying the model files. For example, we add the following to employee.rb:
class Company < xyz =" Company.create(:name"> 'XYZ Corporation')
george = Employee.create(:first_name => 'George',
:last_name => 'Washington',
:email_address => 'georgie@whitehouse.gov',
:company_id => xyz.id)
Now, we can say:
p xyz.employees.first
and we get back our george user. Similarly, we can say:
p george.company
and get back our xyz company. This is all standard stuff for Rails programmers, and it is part of the ActiveRecord feature known as associations. You can create all sorts of associations, giving them arbitrary names. For example, we could say:
class Company < class_name =""> 'Employee',
:conditions => "first_name ilike '%a%'"
end
With this in place, and after restarting the console (or typing reload!), we now can say:
xyz = Company.find_by_name('XYZ Corporation')
xyz.employees_with_a
This prints the empty list—not surprising, given that we have defined only a single employee so far, and his name didn't contain an a. But, now we can create a second employee:
jane = Employee.create(:first_name => 'Jane',
:last_name => 'Austin',
:email_address => 'jane@bookauthor.com',
:company_id => xyz.id)
If we run our association again:
xyz.employees_with_a
now we get our jane employee.
This is all well and good, but what happens if we want to represent different types of employees, each of whom is employed by a company, but with different associated data? This is where polymorphic associations become useful. In order for this to work, we need to change the definitions of our models, as well as the relationships among them (if you're playing along at home, blow away the existing Employee and Company models before continuing):
./script/generate model company name:string
./script/generate model contract employable_id:integer
employable_type:string company_id:integer
./script/generate model programmer main_language:string
first_name:string last_name:string email_address:string
./script/generate model secretary words_per_minute:integer
first_name:string last_name:string email_address:string
The above invocations of script/generate create four different models: one for a company, another for a programmer, another for a secretary and a fourth for a contract. Our PostgreSQL model allowed us to have a single Employee table and to have programmers and secretaries inherit from that table. Rails doesn't let us specify that one model inherits from another. Rather, we use Rails to describe the relationships among the models. Companies are connected to programmers and secretaries via employment contracts.
Because we are looking at the relationships among standalone models, rather than an inheritance hierarchy, there's no obviously good place in which to stick attributes that are common to programmers and secretaries. In the end, I decided to put the attributes in the programmer and secretary models, respectively, despite the repetition.
Now, let's define the associations:
class Company < polymorphic =""> true
end
class Programmer < as =""> :employable
has_many :companies, :through => :contracts
end
class Secretary < as =""> :employable
has_many :companies, :through => :contracts
end
In other words, each company has many contracts. Each contract joins together a company and someone who is employable. Who is employable? Right now, only programmers and secretaries fit the bill, connecting to the employable interface with contracts, and then to a company via a contract.
Behind the scenes, Rails is pulling a nasty trick, one that should make any good database programmer feel sick. The contract model includes two fields (employable_id and employable_type), which point to a single row in a particular table. In some ways, this is sort of a poor man's foreign key. But the difference is that the foreign key can point to any of several tables. And, of course, there is no error checking; only the application can stop me from entering a random text string in the employable_type column.
So, now we can create some relationships:
xyz = Company.create(:name => 'XYZ Corporation')
p1 = Programmer.create(:first_name => 'Linus',
:last_name => 'Torvalds',
:email_address => 'torvalds@osdl.org',
:main_language => 'C')
Contract.create(:employable => p1, :company => xyz)
s1 = Secretary.create(:first_name => 'Condoleezza',
:last_name => 'Rice',
:email_address => 'rice@state.gov',
:words_per_minute => 90)
Contract.create(:employable => s1, :company => xyz)
That's already pretty remarkable. Because both programmers and secretaries are employable (as they both expose the employable interface to the contracts model, using has_many :as), we can join each of them to an instance of the contract model.
But, it gets better, if we add a few more associations:
class Contract < polymorphic =""> true
belongs_to :programmer,
:class_name => 'Programmer', :foreign_key => 'employable_id'
belongs_to :secretary,
:class_name => 'Secretary', :foreign_key => 'employable_id'
end
class Company < through =""> :contracts,
:source => :programmer,
:conditions => "contracts.employable_type = 'Programmer' "
has_many :secretaries, :through => :contracts,
:source => :secretary,
:conditions => "contracts.employable_type = 'Secretary' "
end
With this in place, we now have a complete bidirectional association between programmers and secretaries on one side and companies on the other. Thus, we can say:
>> xyz.programmers
=> [#]
>> xyz.secretaries
=> [#]
But, we also can say:
>> Programmer.find(1).companies
=> [#]
Moreover, we can iterate over xyz.contracts, bringing together the secretaries and programmers models into one package:
>> xyz.contracts.each {c puts c.employable.first_name}
Linus
Condoleezza
Although Rails does not provide inheritance within the models, polymorphic associations make it possible to come close to such functionality. You also get a bunch of convenience functions that make it more natural to work with these additional attributes.
Conclusion
Not all data fits cleanly into two-dimensional tables. When this occurs, you can try to shoehorn your data into an inappropriate container. Or, you can try to use the help that is built in to one or more levels of your software stack. If you use PostgreSQL, inheritance can be really useful. If you use Rails, you can take advantage of polymorphic associations, allowing you to treat two or more models with a common API as similar. This isn't the sort of thing you'll do each day, but it's a useful skill to have on hand for cases when you need to take unusual data.
Resources
To learn how PostgreSQL allows for inheritance, read the on-line manual at www.postgresql.org/docs/8.3/static/ddl-inherit.html.
Rails Cookbook, by Rob Orsini, and published by O'Reilly, has some good information about polymorhphic associations.
The Rails Wiki has some good examples and descriptions of polymorhphic associations at wiki.rubyonrails.org/rails/pages/UnderstandingPolymorphicAssociations.
Reuven M. Lerner, a longtime Web/database developer and consultant, is a PhD candidate in learning sciences at Northwestern University, studying on-line learning communities. He recently returned (with his wife and three children) to their home in Modi'in, Israel, after four years in the Chicago area.
__________________________
Taken From: Linux Journal Issue #173, September 2008
One way to solve this problem is not to use relational databases. Objects can be quite good at handling trees and arrays, as well as inheritance hierarchies. Furthermore, object databases do exist, and the Python-based Zope application framework has demonstrated that it's even possible to have object databases in production. Gemstone's demonstration of Ruby running on top of its Smalltalk VM, with its accompanying object database, means that Ruby programmers soon might have access to similar technology.
But, object databases still are far from the mainstream. Most Web developers have access to a relational database, and not much else. Is there anything that we can do for these people?
This month, we take a look at two different ways we can handle data that doesn't quite fit into a relational database. These techniques are quite different from one another, and they don't even come close to the full range of possibilities you can get with a relational database. But, they both work and are used in production environments—and if your data doesn't seem to fit into standard database paradigms, you might want to consider one of them.
PostgreSQL's Table Inheritance
Some data-modeling issues are typically even harder to deal with. For example, a classic introduction to the world of object-oriented programming describes a human resources department. The HR department tracks employees, all of whom have some common characteristics. But, some employees are programmers, some are secretaries, and some are managers—and each of the employee types has specific data that needs to be associated with them.
In an object-oriented world, it's easy to model this. You create an employee class, and then create multiple subclasses of programmer, secretary and manager. Subclassing creates an “is-a” relationship, such that a programmer is an employee. This means that programmers have all the attributes of an employee, but also have some additional characteristics that distinguish them from an ordinary employee. With these subclasses in place, we then can create an array (or any other data structure) of people in our company, knowing that although some are programmers and others are secretaries, they're all employees and can be treated as such.
Translating this idea to the world of relational databases can be a bit tricky. One solution is to use inheritance in your database tables. PostgreSQL has done this for years; thus, it's called an object-relational database by many users. You can do the following in PostgreSQL, for example:
CREATE TABLE Employees (
id SERIAL,
first_name TEXT NOT NULL,
last_name TEXT NOT NULL,
email_address TEXT NOT NULL,
PRIMARY KEY(id),
UNIQUE(email_address)
);
CREATE TABLE Programmers (
main_language TEXT NOT NULL
) INHERITS(Employees);
CREATE TABLE Secretaries (
words_per_minute INTEGER NOT NULL
) INHERITS(Employees);
INSERT INTO Employees (first_name, last_name, email_address)
VALUES ('George', 'Washington', 'georgie@whitehouse.gov');
INSERT INTO Programmers (first_name, last_name,
email_address, main_language)
VALUES ('Linus', 'Torvalds', 'torvalds@osdl.org', 'C');
INSERT INTO Secretaries (first_name, last_name,
email_address, words_per_minute)
VALUES ('Condoleezza', 'Rice', 'rice@state.gov', 10);
If we ask for all employees in the system, we'll get all three of the people we have entered:
atf=# select * from employees;
id first_name last_name email_address
----+------------+------------+------------------------
1 George Washington georgie@whitehouse.gov
2 Linus Torvalds torvalds@osdl.org
3 Condoleezza Rice rice@state.gov
(3 rows)
Of course, this query shows only the columns of the Employees table, which are common to that table and to those that inherit from it. If we want to find out how many words per minute someone types, we must address that query specifically to the Secretaries table:
atf=# select * from secretaries;
id first_name last_name email_address words_per_minute
----+------------+-----------+----------------+------------------
3 Condoleezza Rice rice@state.gov 10
(1 row)
Notice that the id column for all three tables, which was defined as SERIAL (that is, a nonrepeating incrementing integer), is unique across all three tables.
Polymorphic Associations
The way that PostgreSQL has integrated this type of object hierarchy into its relational system is impressive, flexible and useful. And yet, because it is unique to PostgreSQL, it means that no higher-level, database-agnostic application framework can support it. This especially is true in Ruby on Rails, which tries to treat all databases as similar or identical, going so far as to encourage programmers to use a Ruby-based domain-specific language (migrations) to create and modify database definitions. Using PostgreSQL's inheritance features might work, but it will take a fair amount of twisting to make it compatible with Rails.
Besides, Rails already has a feature, known as polymorphic associations, that lets us work with distinct types of items as if they were part of a single class. This isn't the same as an object hierarchy—we can't say that secretaries and programmers are both types of employees. But, we can say that secretaries and programmers are both employable and treat them as similar via that description.
To begin, you might remember that Rails has something known as associations, which allow us to connect one model to another. For example, let's say that each company has one or more employees. Thus, we can create some simple models. We can generate migrations with:
./script/generate model company name:string
./script/generate model employee first_name:string
last_name:string email_address:string company_id:integer
Then, we can turn the automatically generated migration files into actual database tables with the following:
rake db:migrate
Now, we can indicate that each company can have one or more employees by modifying the model files. For example, we add the following to employee.rb:
class Company < xyz =" Company.create(:name"> 'XYZ Corporation')
george = Employee.create(:first_name => 'George',
:last_name => 'Washington',
:email_address => 'georgie@whitehouse.gov',
:company_id => xyz.id)
Now, we can say:
p xyz.employees.first
and we get back our george user. Similarly, we can say:
p george.company
and get back our xyz company. This is all standard stuff for Rails programmers, and it is part of the ActiveRecord feature known as associations. You can create all sorts of associations, giving them arbitrary names. For example, we could say:
class Company < class_name =""> 'Employee',
:conditions => "first_name ilike '%a%'"
end
With this in place, and after restarting the console (or typing reload!), we now can say:
xyz = Company.find_by_name('XYZ Corporation')
xyz.employees_with_a
This prints the empty list—not surprising, given that we have defined only a single employee so far, and his name didn't contain an a. But, now we can create a second employee:
jane = Employee.create(:first_name => 'Jane',
:last_name => 'Austin',
:email_address => 'jane@bookauthor.com',
:company_id => xyz.id)
If we run our association again:
xyz.employees_with_a
now we get our jane employee.
This is all well and good, but what happens if we want to represent different types of employees, each of whom is employed by a company, but with different associated data? This is where polymorphic associations become useful. In order for this to work, we need to change the definitions of our models, as well as the relationships among them (if you're playing along at home, blow away the existing Employee and Company models before continuing):
./script/generate model company name:string
./script/generate model contract employable_id:integer
employable_type:string company_id:integer
./script/generate model programmer main_language:string
first_name:string last_name:string email_address:string
./script/generate model secretary words_per_minute:integer
first_name:string last_name:string email_address:string
The above invocations of script/generate create four different models: one for a company, another for a programmer, another for a secretary and a fourth for a contract. Our PostgreSQL model allowed us to have a single Employee table and to have programmers and secretaries inherit from that table. Rails doesn't let us specify that one model inherits from another. Rather, we use Rails to describe the relationships among the models. Companies are connected to programmers and secretaries via employment contracts.
Because we are looking at the relationships among standalone models, rather than an inheritance hierarchy, there's no obviously good place in which to stick attributes that are common to programmers and secretaries. In the end, I decided to put the attributes in the programmer and secretary models, respectively, despite the repetition.
Now, let's define the associations:
class Company < polymorphic =""> true
end
class Programmer < as =""> :employable
has_many :companies, :through => :contracts
end
class Secretary < as =""> :employable
has_many :companies, :through => :contracts
end
In other words, each company has many contracts. Each contract joins together a company and someone who is employable. Who is employable? Right now, only programmers and secretaries fit the bill, connecting to the employable interface with contracts, and then to a company via a contract.
Behind the scenes, Rails is pulling a nasty trick, one that should make any good database programmer feel sick. The contract model includes two fields (employable_id and employable_type), which point to a single row in a particular table. In some ways, this is sort of a poor man's foreign key. But the difference is that the foreign key can point to any of several tables. And, of course, there is no error checking; only the application can stop me from entering a random text string in the employable_type column.
So, now we can create some relationships:
xyz = Company.create(:name => 'XYZ Corporation')
p1 = Programmer.create(:first_name => 'Linus',
:last_name => 'Torvalds',
:email_address => 'torvalds@osdl.org',
:main_language => 'C')
Contract.create(:employable => p1, :company => xyz)
s1 = Secretary.create(:first_name => 'Condoleezza',
:last_name => 'Rice',
:email_address => 'rice@state.gov',
:words_per_minute => 90)
Contract.create(:employable => s1, :company => xyz)
That's already pretty remarkable. Because both programmers and secretaries are employable (as they both expose the employable interface to the contracts model, using has_many :as), we can join each of them to an instance of the contract model.
But, it gets better, if we add a few more associations:
class Contract < polymorphic =""> true
belongs_to :programmer,
:class_name => 'Programmer', :foreign_key => 'employable_id'
belongs_to :secretary,
:class_name => 'Secretary', :foreign_key => 'employable_id'
end
class Company < through =""> :contracts,
:source => :programmer,
:conditions => "contracts.employable_type = 'Programmer' "
has_many :secretaries, :through => :contracts,
:source => :secretary,
:conditions => "contracts.employable_type = 'Secretary' "
end
With this in place, we now have a complete bidirectional association between programmers and secretaries on one side and companies on the other. Thus, we can say:
>> xyz.programmers
=> [#
>> xyz.secretaries
=> [#
But, we also can say:
>> Programmer.find(1).companies
=> [#
Moreover, we can iterate over xyz.contracts, bringing together the secretaries and programmers models into one package:
>> xyz.contracts.each {c puts c.employable.first_name}
Linus
Condoleezza
Although Rails does not provide inheritance within the models, polymorphic associations make it possible to come close to such functionality. You also get a bunch of convenience functions that make it more natural to work with these additional attributes.
Conclusion
Not all data fits cleanly into two-dimensional tables. When this occurs, you can try to shoehorn your data into an inappropriate container. Or, you can try to use the help that is built in to one or more levels of your software stack. If you use PostgreSQL, inheritance can be really useful. If you use Rails, you can take advantage of polymorphic associations, allowing you to treat two or more models with a common API as similar. This isn't the sort of thing you'll do each day, but it's a useful skill to have on hand for cases when you need to take unusual data.
Resources
To learn how PostgreSQL allows for inheritance, read the on-line manual at www.postgresql.org/docs/8.3/static/ddl-inherit.html.
Rails Cookbook, by Rob Orsini, and published by O'Reilly, has some good information about polymorhphic associations.
The Rails Wiki has some good examples and descriptions of polymorhphic associations at wiki.rubyonrails.org/rails/pages/UnderstandingPolymorphicAssociations.
Reuven M. Lerner, a longtime Web/database developer and consultant, is a PhD candidate in learning sciences at Northwestern University, studying on-line learning communities. He recently returned (with his wife and three children) to their home in Modi'in, Israel, after four years in the Chicago area.
__________________________
Taken From: Linux Journal Issue #173, September 2008
Subscribe to:
Posts (Atom)